
Developer Preview
Generative AI for Observability.
Observability for Generative AI.
iceburst lets you easily monitor your infrastructure, applications, databases, networks, data streams, microservices & more - all in one unified platform.
Why did we build Iceburst?
Most monitoring tools do the same
They install an agent or poll data through an API, send it to their time-series database, and then provide you with dashboards and charts to look at. This may seem good at first, but it causes more pain than cure when it comes time to scale up to terabytes per day.
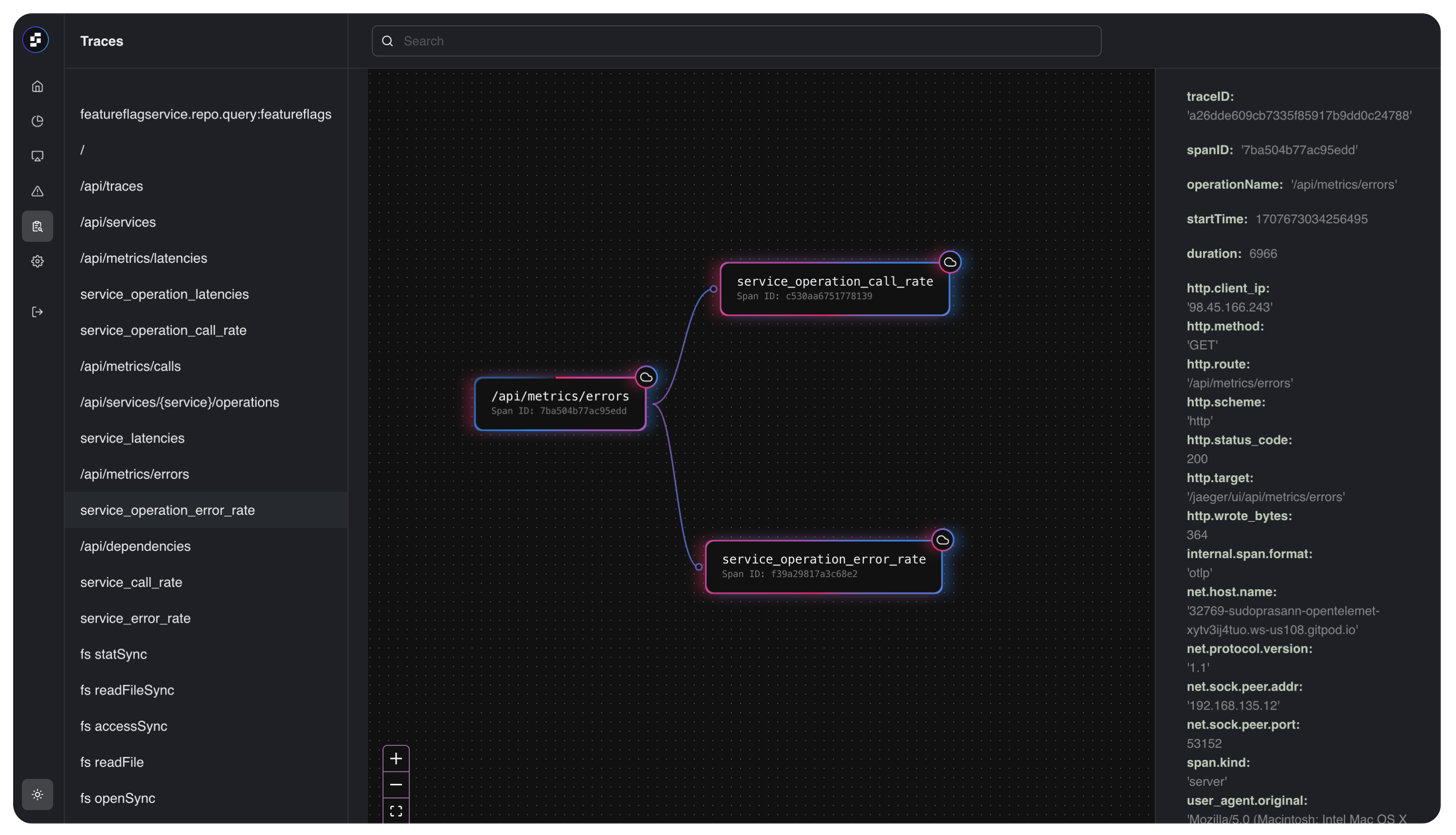
Data Visibility
Latency & Throughput
Pricing Model
Our approach is simple: ingest the OpenTelemetry data in an S3 bucket as Parquet files in Iceberg table format and query them using DuckDB with milliseond retrieval and zero egress cost.

Platform for hypergrowth
Build composable data systems that grows with you. Just like iceberg.

Different by design
iceburst ticks all your checkboxes
Our approach is opinionated, offering tools and systems for monitoring and security. This means that you do not have to build another observability pipeline, provision a Kafka cluster, or manage Flink jobs. We will take care of chaining everything together for you.
Composable
Build composable data systems that grows with your requirements.
Interoperable
Built on open standards like OpenTelemetry, Iceberg and Arrow for interoperability.
Standards
Ibis, Substrait and DuckDB enable standardized SQL query plan execution.
Purpose-built
Move over plain vanilla data tools for development decisions and workflows.
Our Favorite Part
Why developers actually ❤️ iceburst?

The full power of open standards
Join our community of early adopters, advocates and contributors.
"This is the future of databases. It is too expensive / time-consuming to build a DBMS from scratch. If you want a new OLAP DBMS, start with Velox / Arrow+@VoltronData / Clickhouse / @DuckDB. If you want a new OLTP DBMS, start with @PostgreSQL / @RocksDB / @WiredTigerInc."
"In the unbundled OLAP architecture, data is stored directly in object stores like S3 or GCS. Indexing is handled by formats like Hudi and Iceberg, which then structure and provide transactional guarantees over the data to be queried by a distributed query engine like Trino, or in-process with DuckDB."
"All coding projects have two parts - the fun part where you get to create and the painful part where you have to debug. Code LLMs are automating the fun parts while introducing bugs and not helping much with debugging. As a developer, you're left with more pain to deal with. "
Bring your buckets,
we'll handle the rest.
Monitor any stack, any application, at any size, anywhere.